Microservices: Visualize ปัญหา Network Latency ด้วย Zipkin
 |
| src: http://zipkin.io/ |
รู้สึกว่าไม่ได้เขียนหรือพูดอะไรเกี่ยวกับ Microservices มานานรู้สึกแปลกๆ เหมือนกัน แต่วันนี้จับพลัดจับพลูให้ต้องมาจูน Performance Microservices ที่ผมดูแลอยู่ เลยเอาไอเดีย Distributed Tracing ที่เคยลองไว้เมื่อหลายเดือนที่แล้วมาปัดฝุ่นหน่อย
Distributed Tracing
ในยุคที่ทุกคนพูดถึง Microservices กันทั้งบ้านทั้งเมือง เจ็บตัวมากันก็เยอะ สาเหตุหลักๆ คงหนีไม่พ้น Network Latency เคยมั้ยครับ API ตัวนึงต้องเรียก services หลายตัวมากจนไม่รู้ว่า ตกลงมันไปช้าหรือคอขวดอยู่ที่ตัวไหน จะดูจาก Log ที่ webserver พ่นออกมาบางครั้งก็อ่านยาก ตาลาย เยอะไปหมด เชื่อเหอะครับ มันมีคนเจอปัญหาแบบนี้อยู่ทั้งนั้นแหละ |
| src: http://opentracing.io/documentation/ |
ทีนี้หลายคนก็อาจจะเกิดคำถามในใจว่า เห้ยมันจะไม่ยิ่งทำให้ request แต่ละครั้งช้าลงไปกว่าเดิมอีกเหรอเพราะต้องยิงข้อมูลไปเก็บที่เซิร์ฟเวอร์กลาง คือ มันก็ช้าลงนะครับ แต่นิดนึง แต่ละเจ้าก็จะมีเทคนิคที่ทำให้มันส่งผลกระทบต่อ request จริงๆ ให้น้อยที่สุด ยกตัวอย่างเช่นเจ้า Zipkin ที่ผมใช้ในโพสนี้ มันจะแนบ header พิเศษที่บอกว่า request ไหนเป็นพวกเดียวกันไปกับทุก request แล้วจังหวะที่มันยิงข้อมูลไปเก็บกับเซิร์ฟเวอร์กลางก็จะส่งผ่าน http นี่แหละครับแต่ส่งผ่าน Thrift message แทน
 |
| src: http://opentracing.io/documentation/ |
Zipkin
พูดถึงเครื่องมือ ก่อนหน้านี้ผมเคยวัดโดยการปรินต์ time ของ python ไปแปะไว้ตามที่ต่างๆ ซึ่งมันก็ค่อนข้างจะ Flexible แต่เวลารวบรวมผลมาวิเคราะห์มันก็ต้องทำเอง นั่นเป็นอดีตปัจจุบันเรามีเครื่องมือเยอะมากที่จะใช้ทำ Distributed Tracing ขึ้นอยู่กับ Platform ที่เราใช้เลย ยกตัวอย่างเช่น ถ้าคุณ Host อยู่ใน AWS stack มันก็มี service ชื่อว่า AWS X-Ray ไว้สำหรับทำ Distributed Tracing ให้หรือปัจจุบันก็มีมาตรฐานอย่าง OpenTracing อยู่ แต่ตัวที่ผมใช้คือ Zipkin ครับตัว Zipkin เนี่ยถูกพัฒนามาจากเปเปอร์ของ Google ที่มีชื่อว่า Dapper, a Large-Scale Distributed Systems Tracing Infrastructure ในตัวมันเองเนี่ยจะประกอบไปด้วย Collectors ที่คอยรับ Trace ที่ส่งมาจากระบบเรากับ Lookup UI ซึ่งไว้ใช้ในการวิเคราะห์ข้อมูลที่ดักมาได้
วิธีใช้งานเนื่องจากสมัยนี้เรามี Docker แล้วเพราะฉะนั้นจะไปเสียเวลาลงให้มันยากทำไมแค่ setup docker-compose ง่ายๆ ตามนี้ก็รันตัว zipkin server ขึ้นมาได้แล้วครับ
version: '2'
services:
storage:
image: openzipkin/zipkin-mysql
container_name: mysql
zipkin:
image: openzipkin/zipkin
container_name: zipkin
environment:
- STORAGE_TYPE=mysql
- MYSQL_HOST=mysql
ports:
- 9410:9410
- 9411:9411
depends_on:
- storage
dependencies:
image: openzipkin/zipkin-dependencies
container_name: dependencies
entrypoint: crond -f
environment:
- STORAGE_TYPE=mysql
- MYSQL_HOST=mysql
- MYSQL_USER=zipkin
- MYSQL_PASS=zipkin
depends_on:
- storage
สร้าง Trace กัน
เนื่องจาก Framework ที่ผมทำงานเป็นหลักตอนนี้เป็น Python / Django เลยจะมีบางเรื่องที่ค่อนข้างจะ Specific กับ Framework อยู่บ้างแต่หลักการคร่าวๆ ก็น่าจะเอาไปประยุกต์ใช้กับทุก Python Framework ได้หมดเลย โอเค ก่อนอื่นเราต้องลง package ให้ Python คุยกันกับ zipkin ได้ก่อนผ่าน
pip install py_zipkin
import requests
from rest_framework.views import APIView
from py_zipkin.zipkin import zipkin_span, create_http_headers_for_new_span
def http_transport(encoded_span):
body = b'\x0c\x00\x00\x00\x01' + encoded_span
requests.post(
'http://zipkin:9411/api/v1/spans',
data=body,
headers={'Content-Type': 'application/x-thrift'}
)
class SomeGatewayView(APIView):
@zipkin_span(service_name='gateway', span_name='get_service_b')
def get_service_b(self):
zipkin_header = create_http_headers_for_new_span()
response = requests.get(
settings.SERVICE_B_URL + 'resource/',
headers=zipkin_header
)
status_code_200 = response.status_code == status.HTTP_200_OK
return response.json() if status_code_200 else answers
def get(self, request):
with zipkin_span(
service_name='gateway',
span_name='index',
transport_handler=http_transport,
port=8000,
sample_rate=100
):
answers = self.get_service_b()
return Response(answers)
จะมีสิ่งที่ customize นิดหน่อยไล่จากข้างบนเลยคือตัว transport_handler ที่ผมใช้จะเขียนเองไม่ใช้ตัวมาตรฐานที่มาให้ โดยมีหน้าที่ยิง Thrift message ไปหา zipkin server แต่จะยิง encoded_span ไปตรงๆ ก็ไม่ได้เราต้องแอด binary header ที่เห็นเป็น b'\x0c\x00\x00\x00\x01' เพื่อบอกว่านี่คือ Thrift message นะ
ในตัว View จะมีส่วนที่สร้าง span อยู่สองส่วน ทั้งสองอันสร้างโดยใช้ utils ชื่อ zipkin_span ทั้งคู่ซึ่งสามารถทำตัวเป็นได้ทั้ง context manager หรือ decorator หลักๆ เลยคือเราต้องใช้ชื่อ service กับ span ลงไปว่ามันคือจุดไหนของโค้ด แต่ตรง get_service_b จะมีความพิเศษอย่างนึงคือเราจะแนบ zipkin_header ซึ่งถูกสร้างจาก utils create_http_headers_for_new_span ไปให้กับ request ที่ยิงไป service อื่นด้วย
มาที่ service B เราก็ต้องลง py_zipkin package เหมือนกัน แล้วก็เราจะมี function http_transport เหมือนกันเลย ไว้คอยยิง Thrift ไปหา zipkin server หน้าตาประมาณนี้
import requests
from py_zipkin.zipkin import zipkin_span, ZipkinAttrs
from rest_framework.views import APIView
def http_transport(encoded_span):
body = b'\x0c\x00\x00\x00\x01' + encoded_span
requests.post(
'http://zipkin:9411/api/v1/spans',
data=body,
headers={'Content-Type': 'application/x-thrift'}
)
class AnotherAPIView(APIView):
def get(self, request):
with zipkin_span(
service_name='service_b',
zipkin_attrs=ZipkinAttrs(
trace_id=request.META.get('HTTP_X_B3_TRACEID'),
span_id=request.META.get('HTTP_X_B3_SPANID'),
parent_span_id=request.META.get('HTTP_X_B3_PARENTSPANID'),
flags=request.META.get('HTTP_X_B3_FLAGS'),
is_sampled=request.META.get('HTTP_X-B3-SAMPLED')
),
span_name='service_b_api',
transport_handler=http_transport,
port=8000,
sample_rate=100
):
return self.do_something(request)
สิ่งที่แตกต่างจาก Gateway ก็คือใน zipkin_span ของ View เราจะรับ Zipkin Attribute ที่ส่งมาจาก Gateway ซึ่ง Attribute พวกนี้มีไว้สำหรับ Track request แต่ละอันว่ามันจับคู่อยู่กับใคร ตรงนี้จะมีความแปลกของ Django ที่ไม่เหมือน Framework อื่นอย่างนึงคือ Django มันไม่สามารถรับ custom headers ตรงๆ ได้ แต่สิ่งที่เกิดคือมันจะแปลง Header ที่เราส่งมา สมมติว่าชื่อ X-B3-TraceID มันจะแปลงเป็นตัวใหญ่ทั้งหมด แล้วเปลี่ยน hyphen (-) เป็น underscore (_) แถมเติม HTTP_ ไว้ข้างหน้าให้อีกด้วย แล้วเวลาเรียกต้องเรียกผ่าน request.META แทน
หลังจาก setup พวกนี้หมดแล้ว เราลอง request API ที่เราเอา zipkin_span ไปแปะดู ทุกอย่างน่าจะยังรันได้ปกติ แต่ถ้าเราไปเปิด Zipkin UI ที่ http://localhost:9411 เราจะเห็น Trace list หน้าตาประมาณนี้ครับ
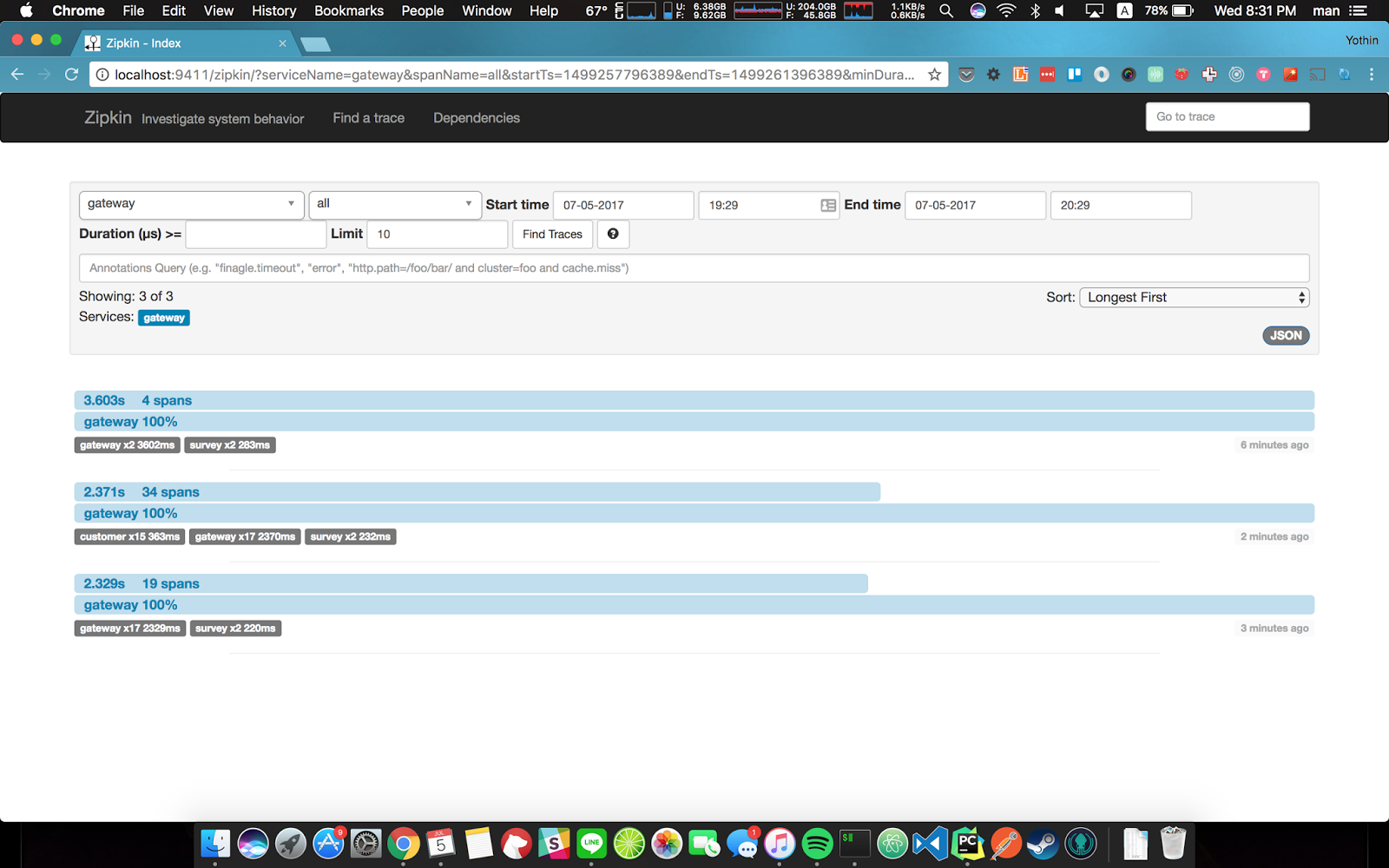 |
| หน้า Trace list ที่เราสามารถ filter หา trace ที่เราสนใจได้ |
 |
| หน้ารายละเอียดใน Trace จะเห็นชัดๆ เลยว่า จุดไหนที่ทำให้ช้า |
{kind=link}
ซึ่งข้างในแต่ละ Trace ถ้าเรากดเข้าไปก็จะเห็นรายละเอียดแต่ละ Span คล้ายๆ ภาพข้างบนเลยครับ ทำให้เราสามารถวิเคราะห์ได้เลย ว่าส่วนไหนที่ทำให้ API Call มันช้าลง นอกจากนี้ในหน้า Dependencies ยังคอยบอกภาพรวมให้เราด้วยว่า service อะไร depend on service อะไร อย่างเช่นในนี้ API Gateway ผมไปเรียก Survey service กับ Customer service แต่ Customer service ก็มี dependency ที่จะต้องไปเรียก survey service ด้วย ทั้งที่ตอนแรกผมไม่ได้เอะใจเลยว่ามันเรียก แต่พอรู้ มันก็ทำให้เราแก้ปัญหาได้ถูกจุดเร็วขึ้น อย่างเคสนี้ ผมแก้โค้ดจาก Customer service ให้ไม่ต้องเรียก Survey service ก็เร็วขึ้นได้หลายเท่าแล้ว อะไรประมาณนี้
 |
| หน้า Dependencies ของระบบ |
 |
| อันนี้หลังจากแก้โค้ดตรงส่วนที่ช้าแล้ว ถ้าดูจาก Zipkin อาจจะเห็นว่าเร็วขึ้นไม่มาก แต่ถ้าลบ Zipkin ออกนี่เร็วขึ้นไปอีก |
Reference
http://zipkin.io/https://github.com/openzipkin/zipkin
http://opentracing.io/documentation/
Comments